This series deals with something a lot of biologists, including microbiologists, don't like to consider (Quantum Biology, 2, 3, 4).
More specifically, this series of Dredd Blog posts deals with the DNA and RNA nomenclature used in GenBank and other genomic repositories which fail to properly distinguish between RNA and DNA to the detriment of our understanding (It's In The GenBank, 2, 3, 4, 5).
For example, the professor in the first video (in the first two minutes) at the bottom of the page pooh-poohs the difference between the two (the rest of the video is worthy).
Today I want to criticize that "parts is parts" approach to DNA and RNA molecules, like I would if someone told me that carbon 12, 13, and 14 aren't different enough to consider a big deal (DOE).
Atoms matter!
II. Appendices
The appendices to today's post show mutant codons (Appendix One) and the differences in atom counts (Appendix Two) in one nucleotide of DNA (T, thymine) compared to the relevant nucleotide of RNA (U, uracil).
The codons and amino acids related to mRNA (mRNA codons have "U" instead of "T") in the lines of Appendix Two follow (are on the following line) the codons of the lines of DNA codons.
This (Appendix Two) shows that the atom counts in DNA 'T' do not match the atom counts of RNA 'U' ('T' parts are not 'U' parts).
Considerable skill is required to move atoms out of or into a molecule, yet that happens during DNA -> mRNA transcription (see videos below).
As it were, one carbon atom and two hydrogen atoms are removed from 'T' which results in 'U' during codon transcription processing.
As you can see in those appendices, this is done in the cells of eucaryotes millions and millions of times daily.
III. Closing Comments
The common practice of some scientists these days is to play dolls with microbes (The Doll As Metaphor, 2, 3, 4).
I say that because way too many scientists support the overuse of antibiotics and other chemicals which kill so many beneficial microbes that they pollute the microbiome with chimeric fogs:
"Chimeras arise when a cell undergoes mutation. This mutation may be spontaneous or it may be induced by irradiation or treatment with chemical mutagens. If the cell which mutates is located near the crest
of the apical dome, then all other cells which are produced by division from it will also be the mutated type. The result will be cells of
different genotypes growing adjacent in a plant tissue, the definition of a chimera."
I have been wondering why the GenBank's "FASTA" format is more preferred than the GBFF format.
I recently decided to use it as the main format for translating DNA segments into mRNA, codons, and amino acids.
Among other things, the GBFF format has errors in its references to genes (e.g. "gene 687..3158"), mRNA, and CDS.
Many of those indicators don't match up with the results when using the technique in the video I displayed below.
That very informative video displayed at the end of this post indicates how translation is done by hand.
Translating by hand is ok for a few lines of DNA, but there are an incredible number of lines in human chromosomes.
It would take an inordinate amount of time to translate them by hand (for example: 22 human chromosomes from a GenBank FASTA file is 2.8 gigabytes in size; the GBFF is even larger).
So, I engineered some software to prepare for "the ribosome job":
"Within all cells, the translation machinery resides within a specialized organelle called the ribosome. In eukaryotes, mature mRNA molecules must leave the nucleus and travel to the cytoplasm, where the ribosomes are located. On the other hand, in prokaryotic organisms, ribosomes can attach to mRNA while it is still being transcribed. In this situation, translation begins at the 5' end of the mRNA while the 3' end is still attached to DNA.
In all types of cells, the ribosome is composed of two subunits: the large (50S) subunit and the small (30S) subunit (S, for svedberg unit, is a measure of sedimentation velocity and, therefore, mass). Each subunit exists separately in the cytoplasm, but the two join together on the mRNA molecule. The ribosomal subunits contain proteins and specialized RNA molecules—specifically, ribosomal RNA (rRNA) and transfer RNA (tRNA). The tRNA molecules are adaptor molecules—they have one end that can read the triplet code in the mRNA through complementary base-pairing, and another end that attaches to a specific amino acid (Chapeville et al., 1962; Grunberger et al., 1969). The idea that tRNA was an adaptor molecule was first proposed by Francis Crick, co-discoverer of DNA structure, who did much of the key work in deciphering the genetic code (Crick, 1958).
Within the ribosome, the mRNA and aminoacyl-tRNA complexes are held together closely, which facilitates base-pairing. The rRNA catalyzes the attachment of each new amino acid to the growing chain."
I has to do with thymine being converted to uracil during the process:
"Like DNA, RNA is a linear polymer made of four different types of nucleotide subunits linked together by phosphodiester bonds (Figure 6-4). It differs from DNA chemically in two respects: (1) the nucleotides in RNA are ribonucleotides—that is, they contain the sugar ribose (hence the name ribonucleic acid) rather than deoxyribose; (2) although, like DNA, RNA contains the bases adenine (A), guanine (G), and cytosine (C), it contains the base uracil (U) instead of the thymine (T) in DNA. Since U, like T, can base-pair by hydrogen-bonding with A (Figure 6-5), the complementary base-pairing properties described for DNA in Chapters 4 and 5 apply also to RNA (in RNA, G pairs with C, and A pairs with U). It is not uncommon, however, to find other types of base pairs in RNA: for example, G pairing with U occasionally."
I added a feature to the software I engineered, which is the addition of the atomic nomenclature of the codons.
Anyway, the next step after converting the 'five-prime' (5`) and 'three-prime' (3`) segments (strands) into mRNA format codons ("U" for uracil, see Fig. 1 above).
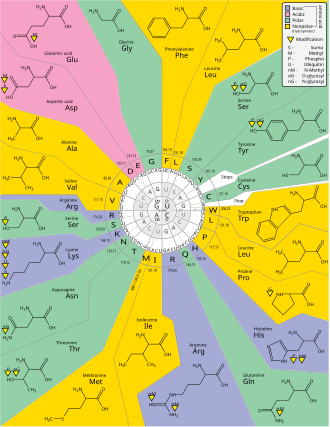
Those codons can then be used to determine the amino acid using the Genetic Code (see Fig. 2).
As I said, I added the atomic nomenclature).
Here is an example from the software's analysis of chromosome 1:
output-files/chr1_fna.html
processing: >CM000663.2 Homo sapiens chromosome 1: GRCh38 reference primary assembly
(Excerpts from chromosome 1). The molecular descriptions in the "molecule content" section are in redletters and digits ; the abbreviations mean: (MET="Methionine", HIS="Histidine", SER="Serine", ARG="Arginine", ASN="Asparagine", LEU="Leucine", and TYR="Tyrosine").
In the "valid codons" section the start and stop codons are in bold letters.
Notice that the software I engineered separates the mutant codons and places them into the "codon mutations" section of the analysis (only one copy of each mutant is displayed).
Proton tunneling has been a suspect in mutant phenomena for some time, so the "codon mutations" section is not useless (The Doll As Metaphor - 4).
More discussion of that and other issues will be forthcoming in future posts in this Dredd Blog series.
The next post in this series is here, the previous post in this series is here.